实时支付状态监控和处理结果的变更
如果2000台机器的实时用户支付状态监控和处理结果的变更,需要构建一个兼具高并发处理能力、毫秒级低延迟响应和持续高可用性的强大后端架构。
其核心设计理念在于确保实时、高效、可靠的数据流转与处理,具体涵盖实时通信、状态同步和高效存储三大关键要素。
高级整体架构设计,搭建运行服务较多,运行维护成本较高
采用分层、解耦的设计原则,由数据采集与通信层、数据接入与缓冲层、实时计算与处理层、数据存储与状态管理层以及监控与告警层构成。
1. 数据采集与通信层:与机器的实时连接
-
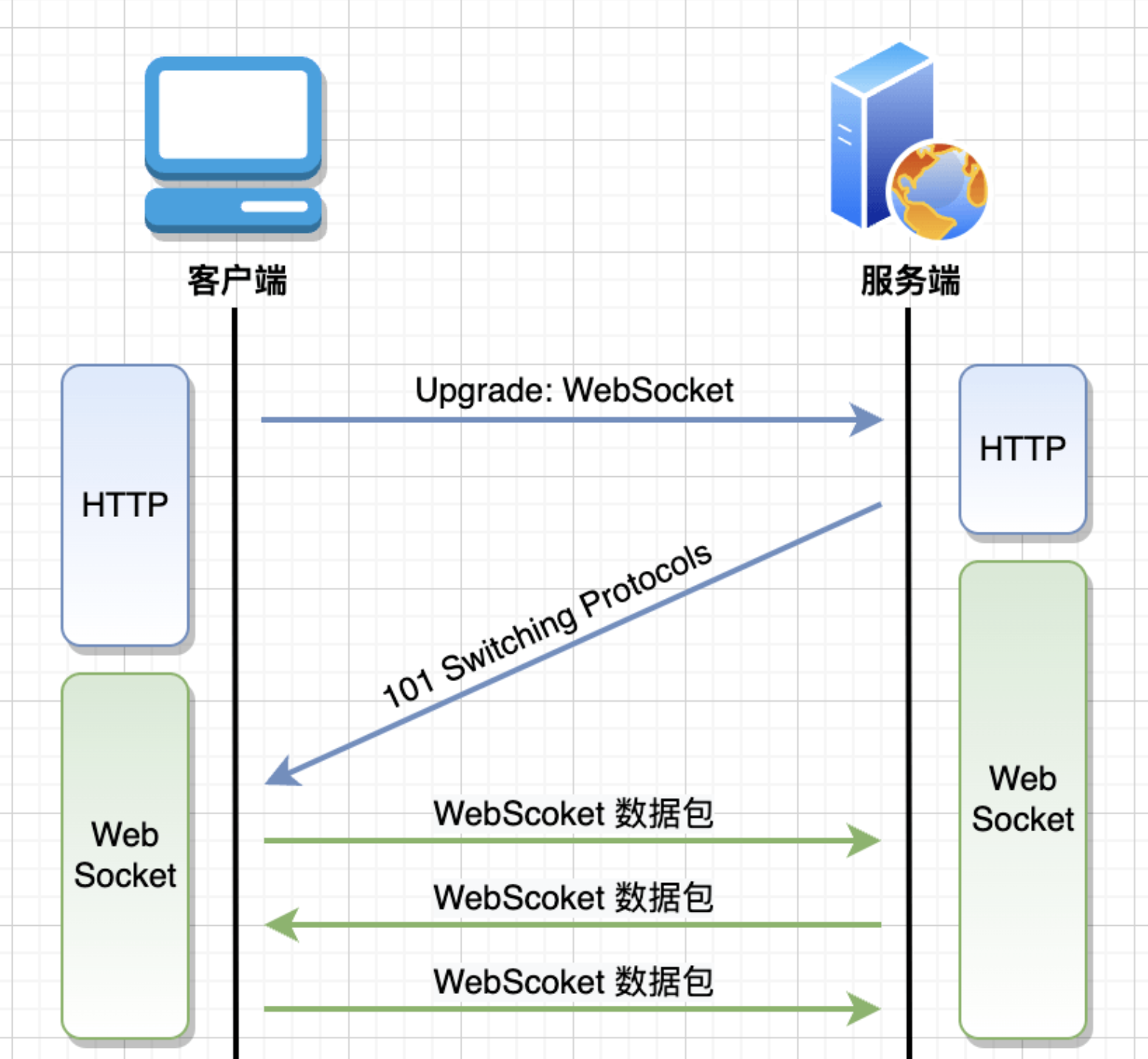
通信协议选择:WebSocket
为了实现服务器与2000台机器之间的低延迟、双向通信,推荐采用 WebSocket。相比于传统的HTTP轮询或长轮询,WebSocket建立持久化连接,允许服务器主动向机器推送状态变更通知,极大地降低了通信延迟和服务器开销。 -
客户端(机器端)设计
机器端的SDK应轻量且高效,负责维护与后端的WebSocket连接,并具备心跳检测和自动重连机制以确保连接的稳定性。当用户发起支付或支付状态发生变化时,SDK将立即通过WebSocket将事件上报。
2. 数据接入与缓冲层:削峰填谷,保证系统稳定
-
消息队列选型:Apache Kafka / RabbitMQ
来自2000台机器的并发请求可能瞬间产生巨大的流量洪峰。为了保护后端应用不被冲垮,引入消息队列进行削峰填谷至关重要。Apache Kafka 是此场景下的理想选择,其具备极高吞吐量、低延迟和高可扩展性的特点,能够轻松应对每秒数十万甚至上百万条消息。Kafka的持久化和分区机制也为数据可靠性和并行处理提供了保障。 -
数据格式
所有上报数据应采用统一的、轻量级的数据格式,如 JSON 。Protobuf在序列化/反序列化效率和数据体积上更具优势,有助于降低网络带宽消耗和处理开销。
3. 实时计算与处理层:核心业务逻辑
-
实时计算引擎:Apache Flink
对于支付状态这种对实时性要求极高的场景,推荐使用 Apache Flink 作为实时计算引擎。Flink是真正的事件驱动型流处理框架,支持事件时间(Event Time)处理和精确一次(Exactly-Once)的状态一致性保证,确保即使在乱序或延迟事件到达时也能产出正确的结果。Flink的毫秒级处理延迟远优于基于微批处理的Spark Streaming。 -
核心处理逻辑
-
支付状态机: 在Flink作业中为每一笔支付订单维护一个状态机,根据上报的事件(如“创建订单”、“支付中”、“支付成功”、“支付失败”、“订单超时”等)驱动状态流转。
-
关联外部信息: Flink作业可以实时关联外部数据源(如用户风控信息、优惠券信息等)进行复杂的业务逻辑判断。
-
处理结果变更: 处理完成后,将结果(如“允许发货”、“交易关闭”等)发送到下游的消息队列,或直接通过API通知相关业务系统。
-
4. 数据存储与状态管理层:高效读写与持久化
-
分布式缓存:Redis
为了实现状态的快速读取和更新,采用 Redis 作为分布式缓存。 Redis基于内存,读写性能极高。支付过程中的中间状态、订单的实时状态等高频访问的数据都应存储在Redis中,以减轻数据库压力。Redis丰富的数据结构(如Hashes、Sorted Sets)也能很好地满足不同业务场景的需求。 -
数据库选型:PostgreSQL /Mysql 或 NoSQL
-
关系型数据库 (PostgreSQL): 对于需要强事务保证和复杂查询的核心交易数据,PostgreSQL 是一个优秀的选择。它在并发处理和对JSON等现代数据类型的支持上表现出色。
-
NoSQL数据库 (MongoDB/ClickHouse):
-
对于支付日志、用户行为等非核心但数据量巨大的数据,可以考虑使用 MongoDB 这类文档型数据库,其灵活的模式设计易于扩展。
-
如果需要对海量历史支付数据进行实时分析和BI查询,ClickHouse 这种列式存储数据库能提供极高的查询性能。
-
-
-
数据一致性
采用数据库与缓存双写的策略,并配合消息队列实现最终一致性,确保在高并发下数据状态的正确同步。
5. 监控与告警层:保障系统健康运行
-
全链路监控: 使用如 Prometheus + Grafana 的组合,对系统各组件(Kafka、Flink、Redis、应用服务等)的核心指标(如QPS、延迟、资源使用率)进行全面监控。
-
日志聚合与分析: 通过 ELK Stack (Elasticsearch, Logstash, Kibana) 或 Loki 聚合所有服务的日志,方便快速定位和排查问题。
-
实时告警: 设置关键指标的告警阈值,一旦系统出现异常(如消息队列积压、Flink作业失败、数据库连接池耗尽等),能通过短信、电话或即时通讯工具立即通知相关人员。
高可用性设计
-
无状态服务: 核心应用服务应设计为无状态,便于水平扩展和快速故障恢复。
-
集群化部署: 所有关键组件(接入网关、Kafka、Flink、Redis、数据库)均采用集群模式部署,避免单点故障。
-
负载均衡: 在应用层前端使用 Nginx 或 LVS 等负载均衡器,将流量分发到多个服务实例。
-
故障自动转移: 利用Kubernetes等容器编排平台的健康检查和自动重启机制,以及数据库和消息队列自身的故障转移能力,实现服务的高可用性。
通过上述架构设计,可以构建一个稳定、高效且可扩展的实时支付监控系统,从容应对2000台机器带来的高并发、低延迟和高可用的挑战。
只允许单用户登录的处理方式
只允许单用户登录问题的处理方式,详细实现流程:
通过两个关键场景来详细描述实现流程:
场景一:用户在设备A首次登录
-
客户端请求登录:
-
用户在设备A上输入用户名和密码,发送登录请求到认证服务。
-
-
认证服务处理:
-
验证用户名和密码是否正确。
-
验证通过后,生成一个唯一的会话标识(Session ID),例如使用JWT (JSON Web Token)。这个Session ID将作为后续所有请求的凭证。
-
【核心步骤】 将用户的活跃会话信息存入 Redis。这里使用一个简单的Key-Value结构:
-
Key: user_active_session:<UserID> (例如: user_active_session:12345)
-
Value: SessionID_A (例如: eyJhbGciOiJIUzI1NiIsIn...)
-
Redis命令: SET user_active_session:12345 "SessionID_A"
-
-
-
建立实时连接:
-
认证服务将生成的 SessionID_A 返回给设备A。
-
设备A的客户端收到 SessionID_A 后,立即向实时通信网关 (WebSocket Gateway) 发起WebSocket连接请求,并在请求中携带 SessionID_A 进行身份验证。
-
-
通信网关注册连接:
-
WebSocket网关收到连接请求,验证 SessionID_A 的合法性(例如解析JWT)。
-
验证通过后,WebSocket网关会维护一个映射关系,用于未来能根据UserID找到对应的连接。这个映射可以存在网关的内存中,或者也存入Redis中(尤其是在网关是集群部署时)。
-
映射: UserID -> WebSocketConnectionID (例如: 12345 -> conn_xyz123)
-
-
至此,设备A登录成功并保持在线。
-
场景二:用户在设备B进行新登录(踢出设备A)
-
客户端请求登录:
-
用户在设备B上输入用户名和密码,发送登录请求到认证服务。
-
-
认证服务处理(踢出逻辑):
-
验证用户名和密码。
-
验证通过后,生成一个新的会话标识 SessionID_B。
-
【核心步骤】 在将新会话写入Redis之前,先获取并替换旧的会话。Redis的 GETSET 命令是原子性的,非常适合此场景。
-
原子操作: GETSET user_active_session:12345 "SessionID_B"
-
结果: 这个命令会返回旧的值 SessionID_A,同时将Key的值更新为 SessionID_B。现在,SessionID_B 成为了唯一合法的会话。
-
-
-
发布“强制下线”事件:
-
认证服务拿到了旧的 SessionID_A(如果存在的话)。它会立即通过一个内部的消息队列 (如Kafka或RabbitMQ) 发布一个“强制下线”事件。
-
事件内容: {"event": "FORCE_LOGOUT", "userId": "12345", "oldSessionId": "SessionID_A"}
-
消息队列为了解耦。认证服务不应该直接与WebSocket网关通信,通过消息队列可以提高系统的健壮性和可扩展性。
-
-
通信网关处理下线事件:
-
实时通信网关 (WebSocket Gateway) 订阅了“强制下线”事件。
-
当它收到该事件后,根据 userId: 12345 查找到对应的旧连接 conn_xyz123。
-
【主动踢出】 网关通过 conn_xyz123 这条WebSocket连接,向设备A的客户端主动发送一条消息。
-
消息内容: {"type": "force_logout", "message": "您已在其他设备登录"}
-
-
发送消息后,服务器主动关闭这条WebSocket连接。
-
-
设备A响应:
-
设备A的客户端收到 force_logout 消息后,应立即执行下线操作:清除本地存储的 SessionID_A 和用户信息,并跳转到登录页面。
-
即使客户端代码出现异常未能正确处理该消息,由于服务器已主动断开连接,设备A也无法再进行任何实时操作。
-
-
设备B完成登录:
-
与此同时,认证服务已将新的 SessionID_B 返回给设备B。
-
设备B走与场景一相同的流程,建立新的WebSocket连接并保持在线。
-
安全性与健壮性:最后的防线
仅仅踢出WebSocket连接是不够的。如果设备A的网络恰好在被踢出前断开,它可能不知道自己已下线。当网络恢复后,它可能会尝试使用旧的 SessionID_A 去请求普通的HTTP API(例如查询订单历史)。
因此,必须有后端防线:
-
API网关/后端服务强校验:
-
所有需要登录才能访问的API,都必须在API网关或服务内部对请求携带的Session ID进行验证。
-
验证逻辑:从Redis中根据 user_active_session:<UserID> 取出当前合法的 Session ID,与请求中携带的 Session ID进行比对。
-
如果请求携带的 SessionID_A 与Redis中存储的 SessionID_B 不匹配,则立即拒绝该请求,返回401 Unauthorized错误。
-
总结
通过以上设计,我们构建了一个三层防御体系来确保单点登录的实现:
-
权威状态层 (Redis): 利用Redis作为唯一、高速的会话状态记录中心。
-
主动通知层 (WebSocket): 在新登录发生时,通过WebSocket主动、实时地通知旧客户端下线。
-
被动验证层 (API校验): 对每一次API请求都进行会话有效性校验,作为最终的、最可靠的防线,杜绝任何使用旧会话操作的可能性。
这样不仅解决了实时T出旧客户端的问题,而且通过组件解耦和多层防御,保证了系统整体的高性能、高可用和高安全性。
向上管理能力决定职业天花板高度
在职场中,我们常常听到“能力决定一切”的说法。然而,现实却告诉我们,仅仅依靠专业能力并不足以让你在职场中脱颖而出。
真正决定你职业天花板高度的,往往是另一种能力——向上管理的能力。
向上管理,并不是简单的讨好上级,而是一种通过有效沟通、资源整合和价值传递,与上级建立良性互动关系的能力。
一、什么是向上管理?
1. 向上管理的定义
向上管理,简单来说,就是通过有效的方式管理和影响你的上级,从而获得更多的资源、支持和机会。它并不是一种单向的服从或讨好,而是一种双向的互动和合作。
2. 向上管理的核心
向上管理的核心在于三点:
理解上级的目标和需求:只有了解上级的优先级和痛点,才能更好地为其提供支持。
提供价值:通过解决问题、创造价值,赢得上级的信任和依赖。
建立信任关系:通过有效的沟通和合作,与上级建立长期的信任关系。
二、为什么向上管理决定职业天花板?
1. 资源分配的关键
在职场中,资源的分配往往掌握在上级手中。无论是项目机会、晋升名额,还是培训资源,都需要通过上级的批准。如果你无法有效管理上级,就很难获得这些资源,从而限制了自己的发展空间。
2. 职业发展的助推器
向上管理不仅能够帮助你获得资源,还能为你提供职业发展的助推器。通过与上级建立良好的关系,你可以获得更多的指导、反馈和机会,从而加速自己的成长。
3. 影响力的放大器
在职场中,影响力是决定你能否脱颖而出的关键因素。通过向上管理,你可以将自己的影响力扩展到更高的层级,从而获得更多的认可和支持。
三、案例分析:向上管理的成功与失败
案例一:小王的“默默无闻”
小王是一名技术骨干,专业能力非常出色。然而,他性格内向,不善于与上级沟通。每次完成任务后,他只是简单地汇报结果,从不主动向上级展示自己的贡献。久而久之,上级对他的印象越来越模糊,甚至忘记了他的存在。
在一次晋升机会中,小王本以为凭借自己的专业能力能够顺利晋升,但最终却被另一位同事抢走了机会。这位同事虽然专业能力不如小王,但他善于向上管理,经常与上级沟通,展示自己的价值。
即使你拥有出色的专业能力,如果无法有效管理上级,也很难获得职业发展的机会。
案例二:小李的“主动出击”
小李是一名市场经理,专业能力一般,但他非常善于向上管理。每次完成任务后,他都会主动向上级汇报进展,并提出自己的建议和思考。他还经常与上级沟通,了解其需求和痛点,并主动提供支持。
在一次重要项目中,小李通过向上管理,成功获得了上级的支持和资源,最终顺利完成了任务。项目结束后,他不仅获得了晋升机会,还成为了上级的得力助手。
即使你的专业能力一般,如果能够有效管理上级,依然可以获得职业发展的机会。
案例三:老张的“信任危机”
老张是一名资深经理,专业能力非常出色,但他与上级的关系一直不太融洽。每次与上级沟通时,他总是强调自己的观点,而忽视了上级的需求和感受。久而久之,上级对他的信任逐渐下降,甚至开始怀疑他的能力。
在一次重要决策中,老张提出了一个非常有价值的建议,但由于缺乏信任,上级并未采纳。最终,项目失败,老张也因此失去了晋升机会。
向上管理的另一个关键点:建立信任关系。即使你拥有出色的专业能力,如果无法与上级建立信任关系,也很难获得支持。
四、如何提升向上管理的能力?
1. 理解上级的目标和需求
向上管理的第一步,是理解上级的目标和需求。只有了解上级的优先级和痛点,才能更好地为其提供支持。例如,你可以通过定期沟通、观察上级的行为和决策,来了解其需求和目标。
2. 提供价值
向上管理的核心,是提供价值。你可以通过解决问题、创造价值,赢得上级的信任和依赖。例如,你可以主动承担重要任务,提出有价值的建议,或者帮助上级解决难题。
3. 建立信任关系
向上管理的关键,是建立信任关系。你可以通过有效的沟通和合作,与上级建立长期的信任关系。例如,你可以保持透明和诚实的沟通,及时反馈进展和问题,或者主动承担责任。
4. 展示自己的贡献
向上管理的另一个重要方面,是展示自己的贡献。你可以通过定期汇报、总结和反思,向上级展示自己的价值和贡献。例如,你可以在每次任务结束后,向上级汇报成果和思考,或者主动提出改进建议。
五、向上管理的误区
1. 讨好上级
向上管理并不是讨好上级,而是一种通过提供价值和建立信任关系,与上级建立良性互动关系的能力。如果你只是为了讨好上级而做出不切实际的承诺,反而会适得其反。
2. 忽视专业能力
向上管理并不是忽视专业能力,而是一种通过有效沟通和资源整合,提升自己职业发展的能力。如果你只注重向上管理而忽视专业能力,最终也会失去上级的信任。
3. 单向沟通
向上管理并不是单向的沟通,而是一种双向的互动和合作。如果你只关注自己的需求和目标,而忽视上级的需求和感受,最终也会失去上级的支持。
六、向上管理的未来趋势
1. 数据驱动的向上管理
随着数据技术的发展,向上管理也将变得更加数据驱动。例如,你可以通过数据分析,了解上级的需求和痛点,从而提供更有针对性的支持。
2. 远程办公中的向上管理
随着远程办公的普及,向上管理也将面临新的挑战和机遇。例如,你可以通过在线沟通工具,保持与上级的透明和高效沟通,从而建立信任关系。
3. 多元化的向上管理
随着职场文化的多元化,向上管理也将变得更加灵活和多样化。例如,你可以通过不同的沟通方式和风格,适应不同上级的需求和偏好。
向上管理的能力,决定职业天花板的高度。在职场中,仅仅依靠专业能力并不足以让你脱颖而出。
只有通过有效沟通、资源整合和价值传递,与上级建立良性互动关系,才能突破职业天花板,实现自己的职业目标。

DevOps及DevOps工具链
DevOps工具链的组成部分
在DevOps领域,工具链是一个核心概念。工具链包括一系列相互关联的技术工具,用于支持从需求分析到测试、部署和运维的全过程。工具链的具体组成部分可能会因组织和项目的不同而有所差异,但常见的组成部分包括以下几个方面。
1、版本控制系统
版本控制系统如Git和Mercurial等,主要用于追踪文件和项目的变更历史。通过版本控制,开发人员可以安全地回滚到以前的版本,也可以方便地查看和比较不同版本之间的差异。
2、持续集成工具
持续集成工具如Jenkins和Travis CI等,用于自动化构建、测试和部署应用程序的过程。这些工具可以帮助开发人员频繁地向主分支提交代码,并自动执行构建、测试和部署步骤,从而降低错误和提高代码质量。
3、自动化测试工具
自动化测试工具如Selenium和JMeter等,用于对应用程序进行功能和性能测试。这些工具可以模拟用户行为,以发现和修复潜在的问题。自动化测试可以显著提高测试效率和覆盖率,并确保应用程序的稳定性和可靠性。
4、容器编排工具
容器编排工具如Kubernetes和Swarm等,用于管理和调度容器化应用程序。这些工具可以自动部署、扩展和管理容器集群,使开发人员可以更轻松地管理和维护应用程序。
5、应用性能管理工具
应用性能管理工具如New Relic和Datadog等,用于监控和分析应用程序的性能。这些工具可以收集和分析实时数据,帮助开发人员快速发现和解决性能问题。
6、日志管理工具
日志管理工具如ELK Stack和Graylog等,用于收集、分析和可视化应用程序的日志。这些工具可以帮助开发人员快速诊断和解决问题,以及优化应用程序的性能和可靠性。
7、配置管理工具
配置管理工具如Ansible和Chef等,用于管理应用程序的配置文件。这些工具可以自动化地管理应用程序的配置,并确保其一致性和安全性。
综上所述,DevOps工具链涉及多个技术工具,这些工具共同帮助开发人员高效地开发、测试、部署和维护应用程序。通过使用这些工具,组织可以实现更高的生产力和更好的软件质量。
DevOps工具链与传统工具链的区别
DevOps工具链与传统工具链的区别主要在于工作流程、工作效率、业务价值实现和人员技能要求。
1、在工作流程方面,DevOps工具链强调的是自动化和端到端的流程,从需求分析到代码开发,从测试到部署,再到运维监控,所有的环节都能够通过自动化的工具进行协调和协作,大大提升了软件开发的速度和质量。而传统的工具链更注重于人力的参与和人为的工作流程控制,往往是由单一的开发人员、测试人员或者运维人员完成,整个流程容易出现不协调的情况,导致效率降低,同时也容易导致工作中出现遗漏和错误。
2、在工作效率方面,DevOps工具链通过自动化的方式大大提升了软件开发的效率。比如,代码自动化测试工具可以快速的测试代码的质量和性能,减少了测试人员的工作量和时间;持续集成和持续部署工具可以自动的将代码编译、测试、打包、部署,大大降低了运维人员的工作量和工作难度。而传统的工具链往往需要开发人员手动的进行代码编译、打包、部署等工作,工作量大、效率低,容易出现人为的错误和遗漏。
3、在业务价值实现方面,DevOps工具链通过自动化的方式提高了软件开发的效率和质量,能够更快的实现业务的价值。而传统的工具链往往需要更长的时间和更高的人力成本才能实现业务价值。
4、在人员技能要求方面,DevOps工具链需要开发人员、测试人员和运维人员具备一定的自动化工具使用能力和团队协作能力。而传统的工具链更注重于人力的参与和工作流程的控制,对人员的技能要求相对较低。
总之,DevOps工具链与传统工具链的区别主要在于工作流程、工作效率、业务价值实现和人员技能要求。
DevOps工具链的未来发展
在当前DevOps工具链的全球化发展中,我们可以预见未来的发展趋势。未来,DevOps工具链将面临更多的挑战和机遇,它们将在这个领域创造更多的价值。以下是一些可能的未来发展趋势:
1、云原生和容器化:随着云原生和容器化技术的日益普及,DevOps工具链将变得更加高效和自动化。这将使DevOps团队能够更快地部署、扩展和优化应用程序。未来,我们将看到更多基于容器的解决方案,它们将提供更好的应用程序生命周期管理和更高的开发效率。
2、智能化和自动化:人工智能和机器学习技术的发展将使DevOps工具链变得更加智能化。未来的DevOps工具将能够自动识别和修复代码缺陷,智能地进行任务调度和资源管理。这将极大地提高开发和运维的效率,同时减少人为错误。
3、安全和隐私:随着网络安全威胁的不断升级,DevOps工具链将越来越重视安全和隐私。未来的DevOps工具将具备更强大的安全防护能力,能够实时检测和防范各种安全威胁。同时,DevOps团队将更加重视数据隐私和合规性,确保开发和运维过程中的数据安全。
4、开源和开放标准:随着开源技术的普及,DevOps工具链将更加依赖于开源项目。这将促使开发者和组织积极参与开源项目的贡献,推动DevOps工具链的创新和发展。同时,开放标准将成为未来DevOps工具链的主流,这将有助于实现跨平台和跨厂商的兼容性和互操作性。
5、边缘计算和物联网:随着边缘计算和物联网技术的发展,DevOps工具链将更好地支持这些新兴技术。未来的DevOps工具将能够更好地处理物联网设备的部署和管理,支持边缘计算环境下的应用程序开发和部署。
在未来,DevOps工具链将继续变革和创新,为开发者和组织带来更高的效率和更好的用户体验。随着技术的不断进步,我们可以期待一个更加智能、高效、安全和开放的DevOps工具链。
持续集成(CI)
持续集成是一种开发实践,要求开发人员频繁地将代码变更集成到共享的主分支中。每次集成都会触发自动化构建和测试流程,以确保代码的质量和稳定性。通过这种方式,团队可以尽早发现并修复集成错误,从而减少开发周期中的问题积累。
持续交付(CD)
持续交付是持续集成的延伸,它确保在代码通过所有测试后,能够自动发布到版本库中,随时准备部署到生产环境。持续交付的目标是拥有一个始终处于可部署状态的代码库,但它并不自动进行生产环境的部署,而是需要人工干预来决定何时部署。
持续部署(CD)
持续部署则是持续交付的进一步自动化,它意味着一旦代码通过了所有测试,就会自动部署到生产环境中,无需人工干预。这种实践极大地加快了软件从开发到用户手中的速度,使得新功能和修复能够更快地触达用户。
通过实施CI/CD,开发团队能够实现更快的迭代速度,更高的代码质量,以及更灵活的市场响应能力。这种实践是现代敏捷开发和DevOps文化中不可或缺的一部分。
Linux系统里面图形接口服务器X server
X server是Linux系统里面图形接口服务器的简称。Windows系统的界面是这个系统不可分割的一部分,各种窗口操作界面显示都是由系统核心直接管理的,而Linux的图形界面并不是系统的必要组成部分,它可以在无界面的条件下运行。当需要Linux提供界面的时候,系统就会建立一个或者数个X server,通过X协议跟窗口管理器交互,由独立于系统的应用程序来产生窗口,状态栏,按钮之类的交互界面。
比较常见的Linux界面操作环境有KDE和GNOME,为它们提供系统支持的就是X server,而并非Linux核心。
总结一下linux图形界面层次关系:
linux本身-->X服务器<-[通过X协议交谈]->窗口管理器(综合桌面环境)-->X应用程序。
介绍两种方法在命令行中打开远程端的图形应用程序。
两台主机A和B(B是linux主机)
1. A是linux
1)在A主机上,打开终端,执行:ssh -X user@B(ssh -X user@ip)
2)然后在A终端上执行B主机上的图形化界面程序,该图形界面可在A主机显示。
2. A是Windows
需要安装支持x server协议的终端工具
2.1 使用MobaXterm(已经集成x server协议)
1)在A主机上,打开MobaXterm,执行:ssh -X user@B(ssh -X user@ip)
2)然后在MobaXterm上执行B主机上的图形化界面程序,该图形界面可在A主机显示。
2.2 xshell
需要安装xmanager
实测MobaXterm的图形响应速度比xmanager要快,推荐MobaXterm。
————————————————
版权声明:本文为CSDN博主「hello_courage」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012247418/article/details/105347383/
JWT详解
1.什么是JWT 在介绍JWT之前,我们先来回顾一下利用token进行用户身份验证的流程: 客户端使用用户名和密码请求登录 服务端收到请求,验证用户名和密码 验证成功后,服务端会签发一个token,再把这个token返回给客户端 客户端收到token后可以把它存储起来,比如放到cookie中 客户端每次向服务端请求资源时需要携带服务端签发的token,可以在cookie或者header中携带 服务端收到请求,然后去验证客户端请求里面带着的token,如果验证成功,就向客户端返回请求数据 这种基于token的认证方式相比传统的session认证方式更节约服务器资源,并且对移动端和分布式更加友好。其优点如下: 支持跨域访问:cookie是无法跨域的,而token由于没有用到cookie(前提是将token放到请求头中),所以跨域后不会存在信息丢失问题 无状态:token机制在服务端不需要存储session信息,因为token自身包含了所有登录用户的信息,所以可以减轻服务端压力 更适用CDN:可以通过内容分发网络请求服务端的所有资料 更适用于移动端:当客户端是非浏览器平台时,cookie是不被支持的,此时采用token认证方式会简单很多 无需考虑CSRF:由于不再依赖cookie,所以采用token认证方式不会发生CSRF,所以也就无需考虑CSRF的防御 而JWT就是上述流程当中token的一种具体实现方式,其全称是JSON Web Token,官网地址:https://jwt.io/ 通俗地说,JWT的本质就是一个字符串,它是将用户信息保存到一个Json字符串中,然后进行编码后得到一个JWT token,并且这个JWT token带有签名信息,接收后可以校验是否被篡改,所以可以用于在各方之间安全地将信息作为Json对象传输。JWT的认证流程如下: 首先,前端通过Web表单将自己的用户名和密码发送到后端的接口,这个过程一般是一个POST请求。建议的方式是通过SSL加密的传输(HTTPS),从而避免敏感信息被嗅探 后端核对用户名和密码成功后,将包含用户信息的数据作为JWT的Payload,将其与JWT Header分别进行Base64编码拼接后签名,形成一个JWT Token,形成的JWT Token就是一个如同lll.zzz.xxx的字符串 后端将JWT Token字符串作为登录成功的结果返回给前端。前端可以将返回的结果保存在浏览器中,退出登录时删除保存的JWT Token即可 前端在每次请求时将JWT Token放入HTTP请求头中的Authorization属性中(解决XSS和XSRF问题) 后端检查前端传过来的JWT Token,验证其有效性,比如检查签名是否正确、是否过期、token的接收方是否是自己等等 验证通过后,后端解析出JWT Token中包含的用户信息,进行其他逻辑操作(一般是根据用户信息得到权限等),返回结果2.为什么要用JWT 2.1 传统Session认证的弊端 我们知道HTTP本身是一种无状态的协议,这就意味着如果用户向我们的应用提供了用户名和密码来进行用户认证,认证通过后HTTP协议不会记录下认证后的状态,那么下一次请求时,用户还要再一次进行认证,因为根据HTTP协议,我们并不知道是哪个用户发出的请求,所以为了让我们的应用能识别是哪个用户发出的请求,我们只能在用户首次登录成功后,在服务器存储一份用户登录的信息,这份登录信息会在响应时传递给浏览器,告诉其保存为cookie,以便下次请求时发送给我们的应用,这样我们的应用就能识别请求来自哪个用户了,这是传统的基于session认证的过程
然而,传统的session认证有如下的问题: 每个用户的登录信息都会保存到服务器的session中,随着用户的增多,服务器开销会明显增大 由于session是存在与服务器的物理内存中,所以在分布式系统中,这种方式将会失效。虽然可以将session统一保存到Redis中,但是这样做无疑增加了系统的复杂性,对于不需要redis的应用也会白白多引入一个缓存中间件 对于非浏览器的客户端、手机移动端等不适用,因为session依赖于cookie,而移动端经常没有cookie 因为session认证本质基于cookie,所以如果cookie被截获,用户很容易收到跨站请求伪造攻击。并且如果浏览器禁用了cookie,这种方式也会失效 前后端分离系统中更加不适用,后端部署复杂,前端发送的请求往往经过多个中间件到达后端,cookie中关于session的信息会转发多次 由于基于Cookie,而cookie无法跨域,所以session的认证也无法跨域,对单点登录不适用 2.2 JWT认证的优势 对比传统的session认证方式,JWT的优势是: 简洁:JWT Token数据量小,传输速度也很快 因为JWT Token是以JSON加密形式保存在客户端的,所以JWT是跨语言的,原则上任何web形式都支持 不需要在服务端保存会话信息,也就是说不依赖于cookie和session,所以没有了传统session认证的弊端,特别适用于分布式微服务 单点登录友好:使用Session进行身份认证的话,由于cookie无法跨域,难以实现单点登录。但是,使用token进行认证的话, token可以被保存在客户端的任意位置的内存中,不一定是cookie,所以不依赖cookie,不会存在这些问题 适合移动端应用:使用Session进行身份认证的话,需要保存一份信息在服务器端,而且这种方式会依赖到Cookie(需要 Cookie 保存 SessionId),所以不适合移动端 因为这些优势,目前无论单体应用还是分布式应用,都更加推荐用JWT token的方式进行用户认证 JWT结构 JWT由3部分组成:标头(Header)、有效载荷(Payload)和签名(Signature)。在传输的时候,会将JWT的3部分分别进行Base64编码后用.进行连接形成最终传输的字符串 JWTString = Base64(Header).Base64(Payload).HMACSHA256(base64UrlEncode(header) "." base64UrlEncode(payload), secret) JWTString=Base64(Header).Base64(Payload).HMACSHA256(base64UrlEncode(header) "." base64UrlEncode(payload),secret)
1.Header JWT头是一个描述JWT元数据的JSON对象,alg属性表示签名使用的算法,默认为HMAC SHA256(写为HS256);typ属性表示令牌的类型,JWT令牌统一写为JWT。最后,使用Base64 URL算法将上述JSON对象转换为字符串保存 { "alg": "HS256", "typ": "JWT" } 2.Payload 有效载荷部分,是JWT的主体内容部分,也是一个JSON对象,包含需要传递的数据。 JWT指定七个默认字段供选择 iss:发行人 exp:到期时间 sub:主题 aud:用户 nbf:在此之前不可用 iat:发布时间 jti:JWT ID用于标识该JWT 除以上默认字段外,我们还可以自定义私有字段,一般会把包含用户信息的数据放到payload中,如下例: { "sub": "1234567890", "name": "Helen", "admin": true } 请注意,默认情况下JWT是未加密的,因为只是采用base64算法,拿到JWT字符串后可以转换回原本的JSON数据,任何人都可以解读其内容,因此不要构建隐私信息字段,比如用户的密码一定不能保存到JWT中,以防止信息泄露。JWT只是适合在网络中传输一些非敏感的信息 3.Signature 签名哈希部分是对上面两部分数据签名,需要使用base64编码后的header和payload数据,通过指定的算法生成哈希,以确保数据不会被篡改。首先,需要指定一个密钥(secret)。该密码仅仅为保存在服务器中,并且不能向用户公开。然后,使用header中指定的签名算法(默认情况下为HMAC SHA256)根据以下公式生成签名 HMACSHA256(base64UrlEncode(header) "." base64UrlEncode(payload), secret) HMACSHA256(base64UrlEncode(header) "." base64UrlEncode(payload),secret) 在计算出签名哈希后,JWT头,有效载荷和签名哈希的三个部分组合成一个字符串,每个部分用.分隔,就构成整个JWT对象
注意JWT每部分的作用,在服务端接收到客户端发送过来的JWT token之后: header和payload可以直接利用base64解码出原文,从header中获取哈希签名的算法,从payload中获取有效数据 signature由于使用了不可逆的加密算法,无法解码出原文,它的作用是校验token有没有被篡改。服务端获取header中的加密算法之后,利用该算法加上secretKey对header、payload进行加密,比对加密后的数据和客户端发送过来的是否一致。注意secretKey只能保存在服务端,而且对于不同的加密算法其含义有所不同,一般对于MD5类型的摘要加密算法,secretKey实际上代表的是盐值 JWT的种类 其实JWT(JSON Web Token)指的是一种规范,这种规范允许我们使用JWT在两个组织之间传递安全可靠的信息,JWT的具体实现可以分为以下几种: nonsecure JWT:未经过签名,不安全的JWT JWS:经过签名的JWT JWE:payload部分经过加密的JWT 1.nonsecure JWT 未经过签名,不安全的JWT。其header部分没有指定签名算法 { "alg": "none", "typ": "JWT" } 并且也没有Signature部分 2.JWS JWS ,也就是JWT Signature,其结构就是在之前nonsecure JWT的基础上,在头部声明签名算法,并在最后添加上签名。创建签名,是保证jwt不能被他人随意篡改。我们通常使用的JWT一般都是JWS 为了完成签名,除了用到header信息和payload信息外,还需要算法的密钥,也就是secretKey。加密的算法一般有2类: 对称加密:secretKey指加密密钥,可以生成签名与验签 非对称加密:secretKey指私钥,只用来生成签名,不能用来验签(验签用的是公钥) JWT的密钥或者密钥对,一般统一称为JSON Web Key,也就是JWK 到目前为止,jwt的签名算法有三种: HMAC【哈希消息验证码(对称)】:HS256/HS384/HS512 RSASSA【RSA签名算法(非对称)】(RS256/RS384/RS512) ECDSA【椭圆曲线数据签名算法(非对称)】(ES256/ES384/ES512)
什么是AARRR
全国大数据交易所及数据交易平台汇总
政府类:
贵阳大数据交易所
http://www.gbdex.com/website/
我国乃至全球第一家大数据交易所, 贵阳大数据交易所发展会员数目突破2000家,已接入225家优质数据源,经过脱敏脱密,可交易的数据总量超150PB,可交易数据产品4000余个,涵盖三十多个领域,成为综合类、全品类数据交易平台。
西咸新区大数据交易所
http://www.chinabdbank.com/index.htm
西咸新区沣西大数据产业发展平台,通过构建有效的市场机制,聚合政府、企业、社会等多类数据资源,整合大数据服务能力,全面运营大秦大数据银行线上服务平台和陕西省社会数据服务大厅线下服务平台。
东湖大数据交易中心
http://www.chinadatatrading.com/
武汉东湖大数据交易中心股份有限公司的业务涵盖数据交易与流通、数据分析、数据应用和数据产品开发等,聚焦“大数据+”产业链,提供有价值的产品和解决方案,帮助用户提升核心竞争力。
华东江苏大数据交易平台
http://www.bigdatahd.com/
华东江苏大数据交易中心(简称BDEX)是在实施“国家大数据战略”大背景下,经国家批准的华东地区首个领先的跨区域、标准化、权威性省级国有大数据资产交易与流通平台,2015年11月成立于国家级大数据产业基地——江苏盐城大数据产业园,承担助推江苏省国有数据增值开放流通、大数据产业发展之重任。
哈尔滨数据交易中心
http://www.hrbdataex.com/
哈尔滨数据交易中心由黑龙江省政府办公厅组织发起并协调省金融办、省发改委、省工信委等部门批准设立。结合政府数据资源、企业数据资源,打造成为立足东三省,辐射全国的大数据交易市场,构建围绕数据的生态系统支撑平台。
上海数据交易中心
https://www.chinadep.com/index.html
上海数据交易中心有限公司(简称“上海数据交易中心”),是经上海市人民政府批准,上海市经济和信息化委、上海市商务委联合批复成立的国有控股混合所有制企业,上海数据交易中心承担着促进商业数据流通、跨区域的机构合作和数据互联、政府数据与商业数据融合应用等工作职能。
中国工信数据
http://www.miit.gov.cn/n1146312/index.html
平台类:
京东万象
https://wx.jdcloud.com/
以数据开放、数据共享、数据分析为核心的综合性数据开放平台,拥有的数据类型主要包括金融、征信、电商、质检、海关、运营商数据
聚合数据
https://www.juhe.cn/
互联网专业数据科技服务商。主要提供两种核心服务:以API数据接口的形式,提供数据服务;以大数据技术,提供数据应用服务。
数据宝
https://www.chinadatapay.com/
中国领先的国有数据资产增值运营服务商,提供 公安、运营商、银联、交通、车辆、企业、税务、气象大数据。
百度智能云云市场
https://cloud.baidu.com/market/list/125
由百度智能云建立的云计算软件或商品的交易与交付平台,下设多个商品品类,包括镜像环境、建站推广、企业应用、人工智能、数据智能、区块链、泛机器人、软件工具、安全服务、上云服务、API服务等,商品数量数千种。
数粮
http://datasl.com/
大数据领域的流通平台,供数据资源和大数据技术应用产品进行交易,支持API接口、数据包下载、定制等交易模式。
阿凡达数据
https://www.avatardata.cn/Docs
API数据接口云服务,专注于数据的采集与分析处理工作,拥有106个数据种类。
HaoService
http://www.haoservice.com/
数据互联服务平台。提供30大类以上基础数据API服务、热门源码交易服务。
发源地
http://www.finndy.com/
大数据应用平台和大数据解决方案提供商。提供数据交易服务,目前总共拥有20246个数据源。
iDataAPI
https://www.idataapi.com/
数据服务提供商,已推出1300多种数据产品和50多种数据分析产品,涵盖30000个网站平台和全球移动APP平台。
天元数据
https://www.tdata.cn/
中国领先的云计算、大数据服务商。数据商品涵盖了线上零售、生活服务、企业数据、农业、资源能化等10大类。提供17个API接口、165个数据集、56个数据报告、278个政府开放数据。
中原大数据交易
http://www.zybigdatae.cn/
数据资源提供商、数据资产运营商和数据交易服务商,向客户提供大数据全产业链平台与技术服务。提供223个API接口、177个数据集、89个数据报告、2个数据应用。
环境云
http://www.envicloud.cn/home?title=0
环境大数据开放平台。拥有3702家注册用户、收录1,041,098,354条环境数据,以积分兑换和免费下载两种方式提供数据服务。
天眼查
https://www.tianyancha.com/vipintro/?jsid=SEM-BAIDU-PZ1907-SY-000100
天眼查收录了1.8亿+家社会实体信息(含企业、事业单位、基金会、学校、律所等),90多种维度信息全量实时更新。
企查查
https://www.qichacha.com/
提供企业工商信息、法院判决信息、关联企业信息、法律诉讼、失信信息、被执行人信息、知识产权信息、公司新闻、企业年报等企业数据交易服务,覆盖全国1.8亿家企业信息。
杭州钱塘大数据交易中心
http://www.qtbigdata.com/index.html
杭州钱塘大数据交易中心有限公司(简称“钱塘数据”)成立于2015年底,是国内一家工业大数据应用和交易平台。
中关村数海大数据交易平台
http://www.shuhaidata.com/
全国第一家数据交易平台,推动数据的流通,发挥数据的商品属性,促成数据交换、整合,将真正带动大数据产业繁荣。
大数据挖掘模型交易平台
http://mx.tipdm.org/
模型算法交易平台,配套完整建模数据,模型实现过程说明及源代码。
APIX
https://www.apix.cn/services/category
APIX是黑格科技旗下的一款SaaS云服务产品,专注为机构提供实时在线用户数据分析,信用评估,第三方数据接入服务。
抓手数据
https://zhuashou.net/
运用区块链底层技术,以生产数据产品、建立数据交易生态圈为主要目标,促进数据的开放共享和数据价值的释放
千教堂
http://d.askci.com/
全球大数据众享平台
中国数据商城
http://www.chinadatastore.cn/index.html
中国领先的大数据交易平台
中国管理大数据
http://www.chn-source.com/
管理大数据RBD=平台运营商+数据供应商
数据星河
http://www.bdgstore.cn/
是全球首款大数据产业链生态平台,基于国际主流的大数据生态技术研发,结合先进的大数据资产运营理念,汇聚全球近千家大数据公司 。
相关阅读:
最全的中国开放数据(Open Data)及政府数据开放平台汇总
国外最全的开放数据(Open Data)及政府数据开放平台汇总
【Open Data】国外开放数据中心及政府数据开放平台汇总
纽约政府开放数据平台
https://opendata.cityofnewyork.us/
美国官网数据超市
提供230,256个数据集、14个数据目录
新加坡政府开放数据平台
提供1700个数据集、9个数据目录
休斯顿市开放数据门户网站
247个数据集、12个数据目录
Academic Torrents
共享大量数据集的分布式系统,提供445.96TB的研究数据
Hadoopilluminated.Com
http://hadoopilluminated.com/hadoop_illuminated/Public_Bigdata_Sets.html
提供国外开放数据网站相关信息,目前已集合35个查询途径
United States Census Bureau
美国人口普查局
Usgovxml.Com
USGovXML.com是美国政府提供的公共Web服务和XML数据源的索引。USGovXML.com索引来自 美国政府所有3个分支机构以及董事会,委员会,公司和独立机构的数据来源。
Enigma.Com
快速搜索和分析政府、公司和组织发布的数十亿份公共记录。
Datahub.Io
发现和分享高质量数据集,与他人联系和分享知识。
Aws.Amazon.Com/Datasets
https://registry.opendata.aws/
帮助人们发现和共享通过AWS资源提供的数据集。
Databib.Org
开放数据网站导航
Quandl.Com
金融,经济和替代数据集的主要来源,为投资专业人士提供服务。Quandl的平台被超过40万人使用,其中包括来自世界顶级对冲基金,资产管理公司和投资银行的分析师。
Figshare.Com
研究论文上传网站,已有2600万+浏览量、750万+下载、800,000+上传、200万+文章
GeoLite Legacy Downloadable Databases
https://dev.maxmind.com/geoip/geoip2/geolite2/
IP地理定位数据库
Quora's Big Datasets Answer
https://www.quora.com/Where-can-I-find-large-datasets-open-to-the-public
公共开放数据集汇总
Kaggle Datasets
https://www.kaggle.com/datasets
数据文档,拥有20394个数据集
A Deep Catalog Of Human Genetic Variation
https://www.internationalgenome.org/data
国际基因组样本资源
Google Public Data
https://www.google.com/publicdata/directory
谷歌公开数据搜索网站
World Bank Data
世界银行开放数据搜索网站
NYC Taxi Data
http://chriswhong.github.io/nyctaxi/
纽约出租车数据开放平台
Open Data Philly
https://www.opendataphilly.org/
费城开放数据平台、16个数据目录、354个数据集
Grouplens.Org
https://grouplens.org/datasets/
提供9个数据集,关于书籍、电源、wiki数据集
UC Irvine Machine Learning Repository
http://archive.ics.uci.edu/ml/index.php
加州大学欧文机器学习库,提供481个数据集
Research-Quality Data Sets By Hilary Mason
http://web.archive.org/web/20150320022752/https://bitly.com/bundles/hmason/1
公共数据集汇总
National Climatic Data Center - NOAA
美国国家环境信息中心,监测,评估和提供国家气候和历史天气数据和信息
ClimateData.Us
美国宇航局公布的美国气候数据
R/Datasets
https://www.reddit.com/r/datasets/
开放数据集汇总网站
MapLight
关于货币的数据集
GHDx
健康指标和评估研究所 - 来自世界各地的健康和人口统计数据集目录,包括IHME结果
St. Louis Federal Reserve Economic Data - FRED
圣路易斯联邦储备银行数据开放网站,该网站提供丰富的经济数据和信息,以促进经济教育和加强经济研究。
New Zealand Institute Of Economic Research – Data1850
新西兰经济研究所,可在该网站下载自1850年以来的相关经济数据。
Dept. Of Politics @ New York University
http://www.nyu.edu/projects/politicsdatalab/datasupp_datasources.html
纽约大学政治数据中心
Open Data Sources
https://github.com/datasciencemasters/data
Github网站上的开放数据源总结
UNICEF Statistics And Monitoring
https://www.unicef.org/statistics/index_24287.html
联合国儿童基金会官网,开放世界各国家、地区的儿童状况报告
Undata
http://data.un.org/Default.aspx
联合国国际统计数据库,包含6,000多万个数据点,涵盖广泛的统计主题,包括农业,犯罪,通信,发展援助,教育,能源,环境,金融,性别,健康,劳动力市场,制造业,国民核算,人口与移民,科学技术,旅游,运输和贸易。
NASA SocioEconomic Data And Applications Center - SEDAC
https://sedac.ciesin.columbia.edu/
社会经济数据和应用中心,是美国国家航空航天局地球观测系统数据和信息系统(EOSDIS)中的分布式主动档案中心(DAAC)之一。
The GDELT Project
https://www.gdeltproject.org/#intro
GDELT博客是世界上最大的人类社会开放研究平台的最新新闻,公告,信息和应用程序的官方一站式存储库。
Sweden, Statistics
瑞典统计局,提供瑞典国家统计数据,包含26个数据集。
Github Free Data Source List
https://www.datasciencecentral.com/profiles/blogs/great-github-list-of-public-data-sets
Github公共数据集
StackExchange Data Explorer
https://data.stackexchange.com/
一个开源工具,用于对来自StackExchange网络的公共数据进行任意查询。
San Fransisco Government Open Data
旧金山政府开发数据网站
IBM Blog Abour Open Data
https://www.datasciencecentral.com/profiles/blogs/the-free-big-data-sources-everyone-should-know
数据科学中心
Liver Tumor Segmentation Challenge Dataset
https://competitions.codalab.org/competitions/17094
Public Git Archive
https://github.com/src-d/datasets/tree/master/PublicGitArchive
Git Hub开放数据平台汇总
GHTorrent
Microsoft Research Open Data
来自Microsoft Research的免费数据集,以推进自然语言处理,计算机视觉和特定领域科学等领域的最新研究。
Open Government Data Platform India
印度开放政府数据(OGD)平台-data.gov.in-是一个用于支持印度政府开放数据倡议的平台。
Google Dataset Search (Beta)
https://toolbox.google.com/datasetsearch
谷歌数据集搜索门户
Data.Gov
它是美国政府免费提供有关气候和犯罪等各种惊人信息的门户。
Data.Gov.Uk
有来自英国所有中央部门以及许多其他公共部门和地方当局的数据集。它充当有关一切信息的门户,包括商业与经济,犯罪与正义,国防,教育,环境,政府,卫生,社会和交通运输。
美国人口普查局(US Census Bureau)
该网站是有关政府掌握的有关美国公民生活的统计数据,包括人口,经济,教育,地理等。
中央情报局世界概况
https://www.cia.gov/library/publications/the-world-factbook/
世界上每个国家的事实;重点研究267个国家/地区的历史,政府,人口,经济,能源,地理,通讯,运输,军事和跨国问题。
欧盟开放数据门户
http://open-data.europa.eu/en/data/
数据的增长包括欧盟内部的经济发展以及欧盟机构内部的透明度,包括地理,地缘政治和金融数据,统计数据,选举结果,法律法规以及犯罪,健康,环境,交通运输和科学研究的数据。
加拿大开放数据
包含许多政府和地理空间数据集的试点项目。它可以帮助您探索加拿大政府如何通过开放数据,开放信息和开放对话来提高透明度,加强问责制,提高公民参与度并推动创新和经济机会。
Datacatalogs.Org
https://opengovernmentdata.org/
它提供来自美国,欧盟,加拿大,CKAN等的开放政府数据。
美国国家教育统计中心
国家教育统计中心(NCES)是收集和分析与美国和其他国家/地区的教育相关数据的主要联邦实体。
英国数据服务
https://www.ukdataservice.ac.uk/
英国数据服务集合包括英国政府资助的主要调查,跨国调查,纵向研究,英国人口普查数据,国际总量,商业数据和定性数据。
支持博主

关于邵珠庆博客
文章标签
记事邵珠庆博客
最近文章
最近评论
- 发表在《中国翻墙网民状况调查》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
- 发表在《教你如何简单获取新浪微博短地址接口》
博客日历
| 一 | 二 | 三 | 四 | 五 | 六 | 日 |
|---|---|---|---|---|---|---|
| « 8月 | ||||||
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
目录分类
文章归档
- 2025年8月 (2)
- 2022年9月 (1)
- 2022年8月 (3)
- 2022年7月 (1)
- 2022年3月 (1)
- 2021年10月 (3)
- 2021年1月 (1)
- 2020年4月 (3)
- 2020年3月 (3)
- 2020年2月 (2)
- 2020年1月 (3)
- 2019年12月 (2)
- 2019年11月 (3)
- 2019年10月 (2)
- 2019年9月 (2)
- 2019年8月 (4)
- 2019年7月 (2)
- 2019年6月 (2)
- 2019年5月 (2)
- 2019年4月 (3)
- 2019年3月 (2)
- 2019年2月 (3)
- 2019年1月 (2)
- 2018年12月 (2)
- 2018年11月 (2)
- 2018年10月 (3)
- 2018年9月 (2)
- 2018年8月 (2)
- 2018年7月 (1)
- 2018年6月 (2)
- 2018年5月 (3)
- 2018年4月 (2)
- 2018年3月 (6)
- 2018年2月 (7)
- 2018年1月 (3)
- 2017年11月 (2)
- 2017年10月 (2)
- 2017年9月 (5)
- 2017年8月 (4)
- 2017年7月 (8)
- 2017年6月 (5)
- 2017年5月 (14)
- 2017年4月 (8)
- 2017年3月 (5)
- 2017年2月 (2)
- 2017年1月 (1)
- 2016年12月 (1)
- 2016年11月 (5)
- 2016年10月 (3)
- 2016年9月 (2)
- 2016年8月 (1)
- 2016年7月 (2)
- 2016年6月 (2)
- 2016年5月 (5)
- 2016年4月 (5)
- 2016年3月 (2)
- 2016年2月 (1)
- 2016年1月 (2)
- 2015年12月 (2)
- 2015年11月 (1)
- 2015年10月 (3)
- 2015年9月 (2)
- 2015年8月 (4)
- 2015年7月 (5)
- 2015年6月 (6)
- 2015年5月 (3)
- 2015年4月 (8)
- 2015年3月 (6)
- 2015年2月 (4)
- 2015年1月 (5)
- 2014年12月 (2)
- 2014年11月 (5)
- 2014年10月 (5)
- 2014年9月 (1)
- 2014年8月 (2)
- 2014年7月 (4)
- 2014年6月 (1)
- 2014年5月 (9)
- 2014年4月 (5)
- 2014年3月 (1)
- 2014年2月 (1)
- 2014年1月 (5)
- 2013年12月 (4)
- 2013年11月 (12)
- 2013年10月 (6)
- 2013年9月 (7)
- 2013年8月 (8)
- 2013年7月 (15)
- 2013年6月 (9)
- 2013年5月 (12)
- 2013年4月 (8)
- 2013年3月 (11)
- 2013年2月 (9)
- 2013年1月 (21)
- 2012年12月 (8)
- 2012年11月 (7)
- 2012年10月 (19)
- 2012年9月 (16)
- 2012年8月 (13)
- 2012年7月 (10)
- 2012年6月 (11)
- 2012年5月 (11)
- 2012年4月 (8)
- 2012年3月 (8)
- 2012年2月 (11)
- 2012年1月 (8)
- 2011年12月 (18)
- 2011年11月 (32)
- 2011年10月 (17)
- 2011年9月 (18)
- 2011年8月 (11)
- 2011年7月 (55)
- 2011年6月 (1)
- 2011年5月 (4)
- 2011年4月 (2)
- 2011年3月 (1)
- 2011年1月 (3)
- 2010年12月 (1)
- 2010年11月 (6)
- 2010年9月 (5)
- 2010年8月 (2)
- 2010年7月 (3)
- 2010年6月 (7)
- 2010年5月 (3)
- 2010年4月 (4)
- 2010年3月 (8)
- 2010年2月 (2)
- 2010年1月 (2)
- 2009年12月 (2)
- 2009年11月 (1)
- 2009年10月 (1)
- 2009年8月 (1)
- 2009年7月 (2)
- 2009年5月 (1)
- 2009年4月 (1)
- 2009年3月 (1)
- 2009年2月 (1)
- 2009年1月 (1)
- 2008年12月 (1)
- 2008年11月 (2)
- 2008年10月 (1)
- 2008年8月 (5)
- 2008年7月 (2)
- 2008年6月 (1)
- 2008年5月 (3)
- 2008年4月 (11)
- 2008年3月 (1)
- 2008年2月 (1)
- 2008年1月 (1)
- 2007年12月 (1)
- 2007年11月 (3)
- 2007年10月 (1)
- 2007年9月 (1)
- 2007年8月 (1)
- 2007年7月 (1)
- 2007年6月 (1)
- 2007年5月 (1)
博客功能
京东好物
